Understanding Embeddings: The Hidden Layer Behind Language Models
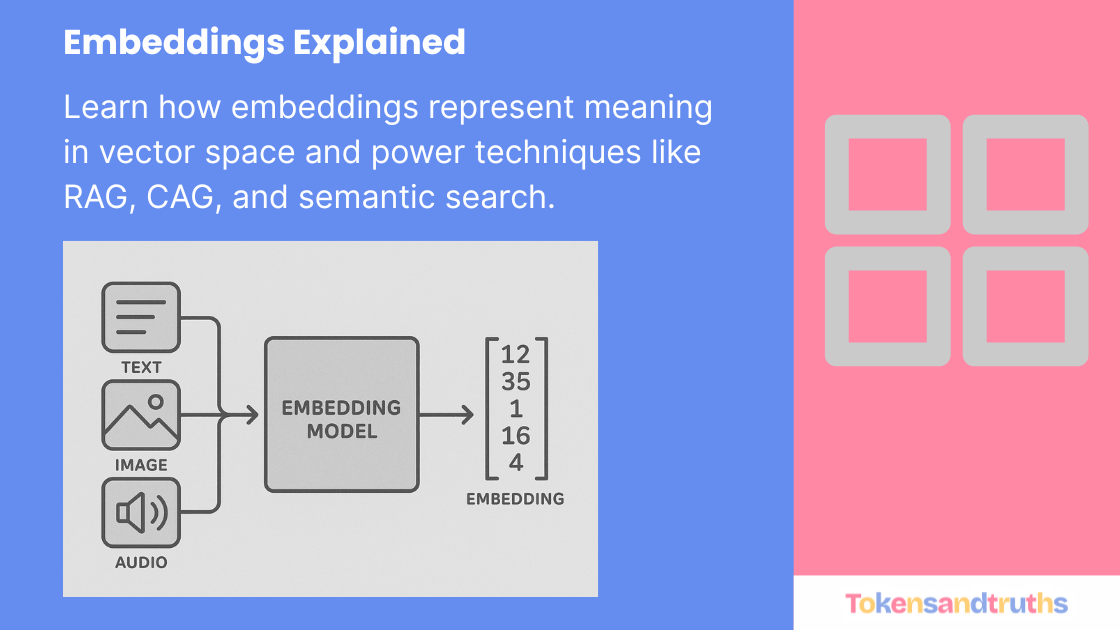
In our previous blog posts, we explored the foundation of Language AI and the role of tokenizers. A tokenizer’s job is simple but essential: it breaks down text into smaller pieces — called tokens — that a Large Language Model (LLM) can process.
For example:
Input:]
"What is large language model?"
Tokenizer Output:
[4827, 382, 4410, 6439, 2359, 30
You can try this yourself using OpenAI’s Tokenizer.
So far, so good — we’ve turned text into numbers.
But here’s the real question:
How does the model understand the meaning behind those numbers?
From Tokens to Meaning: Enter Embeddings
While tokenization gives structure, embeddings give semantics — meaning and context.
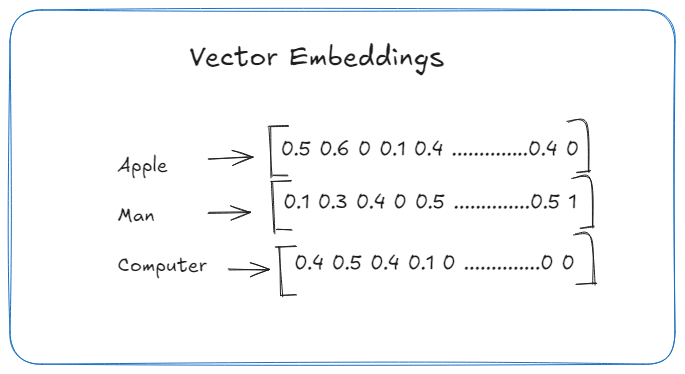
An embedding is a mathematical representation of text (a word, sentence, or even an entire document) in a multi-dimensional space. It helps computers understand how similar or different two pieces of text are.
Think of it like assigning every word a unique address in a vast coordinate system:
- Words with similar meanings live close together.
- Words with different meanings are far apart.
If we visualize it, you’d see clusters of related words like this:
(car, truck, van) → close together
(apple, banana, mango) → close together
(car, banana) → far apart
This geometric relationship between meanings is what powers modern AI’s ability to “understand” language.
A Quick Example: Word Embeddings with Gensim
Let’s start simple. Using the popular Gensim library, we can explore embeddings trained on large text datasets.
import gensim.downloader as api
dataset_name = 'glove-twitter-25'
model = api.load(dataset_name)
model.most_similar("car")Output:
[('front', 0.93), ('on', 0.90), ('table', 0.89), ('truck', 0.88), ('bus', 0.87), ('train', 0.87)]
Notice that truck, bus, and train are among the most similar words to car — the embedding model captures semantic relationships.
Word embeddings like these are powerful for:
- Named entity recognition (NER)
- Text classification
- Clustering or topic modeling
But they only work at the word level.
When we deal with sentences, paragraphs, or entire documents, we need more powerful models.
Sentence and Document Embeddings
Modern LLMs use embedding models that go far beyond words.
They capture the meaning of entire sentences or documents, not just individual terms.
Here’s how you can generate embeddings using Hugging Face’s Sentence Transformers:
from sentence_transformers import SentenceTransformer
model_name = 'thenlper/gte-small'
model = SentenceTransformer(model_name)
sentences = ["What is a large language model?", "How to play cricket?"]
embeddings = model.encode(sentences)Each sentence now becomes a long list of floating-point numbers — its unique “fingerprint” in vector space.
To see how similar two embeddings are, we can use cosine similarity, Euclidean distance, or dot product.
from sklearn.metrics.pairwise import cosine_similarity
from scipy.spatial.distance import euclidean
import numpy as np
def find_similarity(embedding1, embedding2):
cosine_distance = cosine_similarity([embedding1], [embedding2])[0][0]
euclidean_distance = euclidean(embedding1, embedding2)
dot_product = np.dot(embedding1, embedding2)
print("Cosine Distance:", cosine_distance)
print("Euclidean Distance:", euclidean_distance)
print("Dot Product:", dot_product)These similarity scores help LLMs find the most relevant chunks of information — a critical step in advanced techniques like RAG, CAG, and KAG.
Embeddings in Action: Powering RAG, CAG, and KAG
Whenever you interact with a chatbot, search system, or AI knowledge assistant, embeddings work behind the scenes to retrieve the most relevant context.
Here’s how it works:
- Your input is converted into an embedding vector.
- This vector is compared to millions of stored vectors in a vector database like Pinecone, Milvus, or Weaviate.
- Using cosine similarity or Euclidean distance, the system finds content that’s semantically similar to your query.
- The retrieved content is then used by the LLM to generate a grounded, context-aware response.
This entire process — known as Retrieval Augmented Generation (RAG) — makes LLMs far more powerful and reliable.
Why Developers Should Care
As a developer, understanding embeddings unlocks a new set of possibilities:
- Build semantic search engines that find meaning, not keywords.
- Create recommendation systems that understand user intent.
- Power AI assistants that remember and reason over large corpora of data.
- Enable contextual retrieval in your LLM applications.
In short, embeddings are the bridge between numbers and meaning — the foundation of everything from chatbots to intelligent search.
Learn More
If you want to explore embeddings further:
Final Thoughts
While tokenizers break text into pieces, embeddings bring understanding.
They allow models to move beyond syntax into semantics — turning plain text into meaningful mathematical relationships.
Next time your LLM responds with uncanny contextual awareness, remember:
It’s all thanks to the embedding model quietly working behind the scenes.