Types of Generative AI Models
(Text↔Text, Text→Image, Image→Text, Text→Video, Text→Audio, Audio→Text)
Introduction
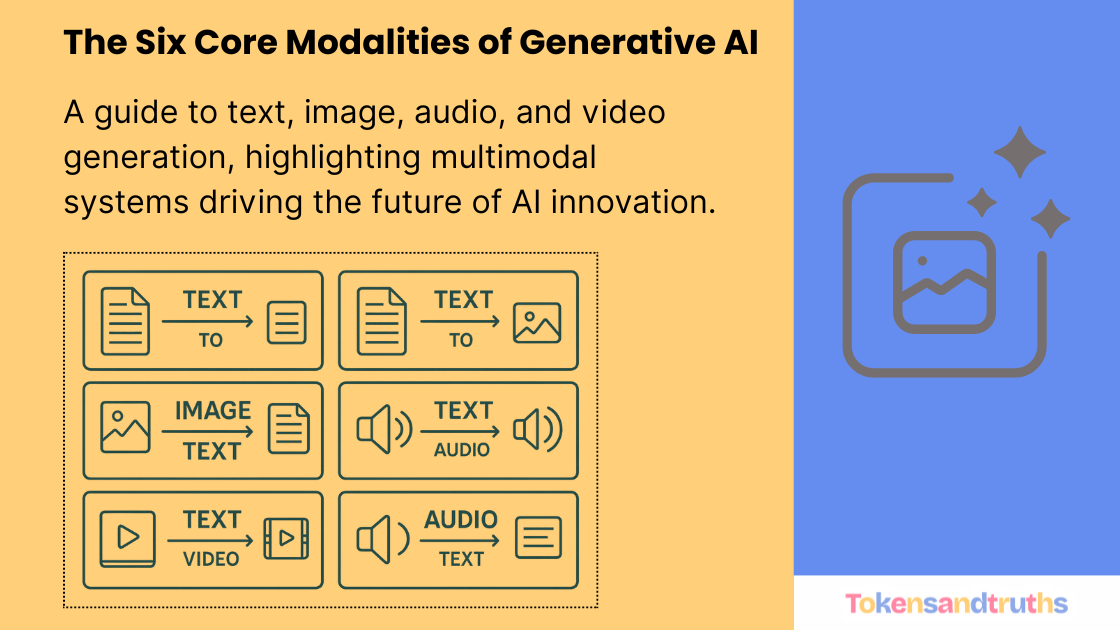
Generative AI is no longer just about writing text. It can now create images, describe photos, read and speak, and even generate short videos. A helpful way to think about this space is in terms of six common transformations, or modalities:
- Text → Text
- Text → Image
- Image → Text
- Text → Video
- Text → Audio (Speech)
- Audio → Text
At the end, I’ll also touch on multimodal models, which can handle more than one of these at once.
1) Text → Text
What it is
You give the model text, it returns text. This includes chatbots, summarizers, translators, and code generators.
Typical models
Llama, Qwen, Microsoft Phi, DeepSeek R1. A popular instruction-tuned example is Llama 3.1 8B Instruct:
https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct
Example prompt
“Can you write a program to upload a file into S3?”
import boto3
from botocore.exceptions import NoCredentialsError
# Set your AWS credentials and S3 bucket name
AWS_ACCESS_KEY_ID = 'YOUR_ACCESS_KEY_ID'
AWS_SECRET_ACCESS_KEY = 'YOUR_SECRET_ACCESS_KEY'
S3_BUCKET_NAME = 'your-bucket-name'
# Create an S3 client
s3 = boto3.client('s3', aws_access_key_id=AWS_ACCESS_KEY_ID,
aws_secret_access_key=AWS_SECRET_ACCESS_KEY)
def upload_file_to_s3(file_path, bucket_name, object_name):
try:
# Upload the file to S3
s3.upload_file(file_path, bucket_name, object_name)
print(f"File uploaded to {bucket_name}/{object_name}")
except FileNotFoundError:
print(f"File {file_path} not found")
except NoCredentialsError:
print("Credentials not available")
except Exception as e:
print(f"Error uploading file: {e}")
# Example usage
file_path = '/path/to/your/file.txt'
object_name = 'file.txt'
upload_file_to_s3(file_path, S3_BUCKET_NAME, object_name)Notes for readers
- Instruction-tuned models usually follow directions better.
- Verify facts. These models can sound confident and still be wrong.
- If you need creative ideas, increase temperature. If you need precision, lower it.
2) Text → Image
What it is
You describe an image in words, the model generates a picture that matches your description.
Typical models
DALL·E, Stable Diffusion (for example, SD 3.5 Large), MidJourney, Flux.
Example model card: https://huggingface.co/stabilityai/stable-diffusion-3.5-large
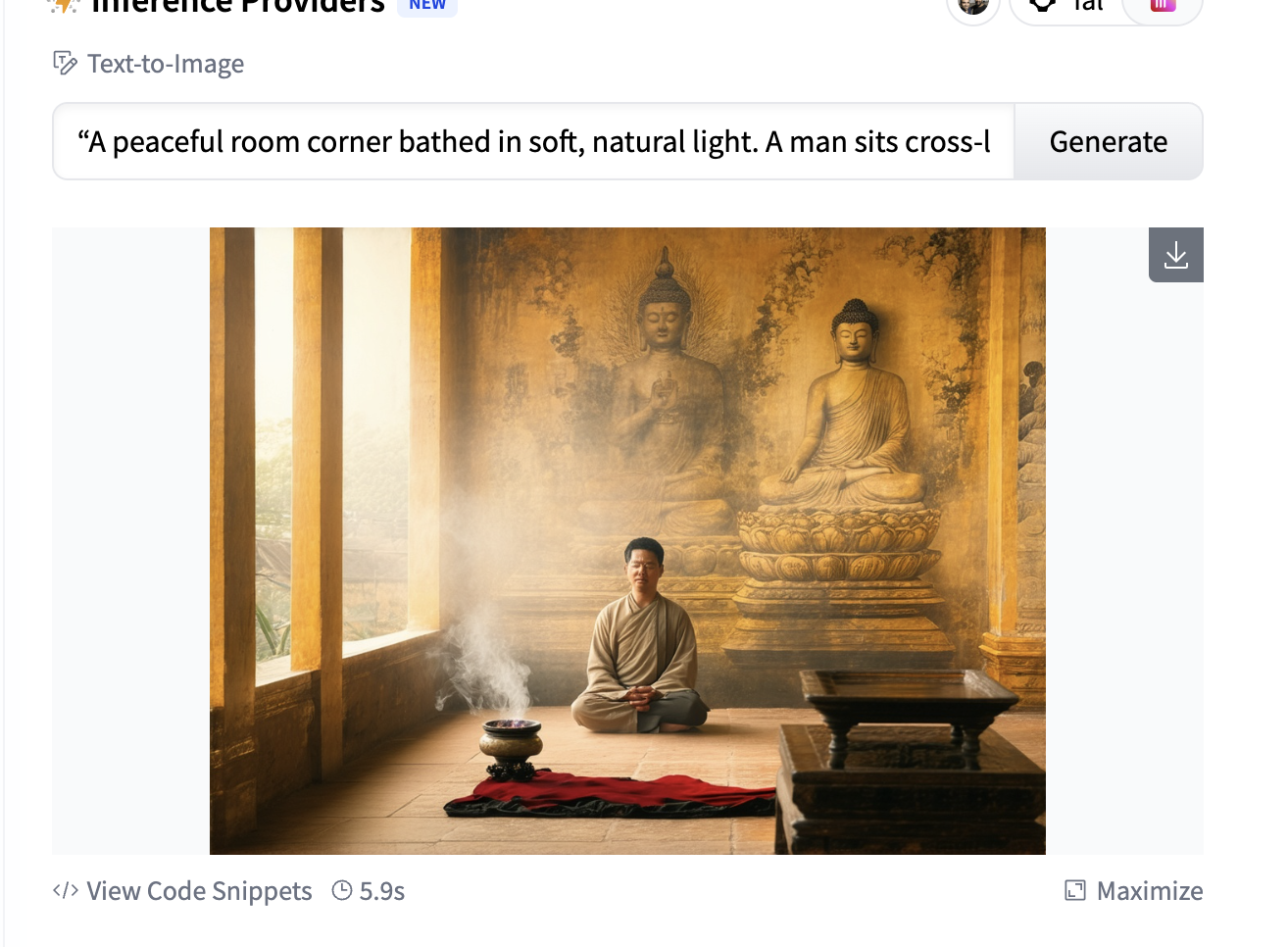
“A peaceful room corner bathed in soft, natural light. A man sits cross-legged in a meditation pose with eyes closed, calm and centered. The walls are beautifully painted with intricate Buddha murals radiating wisdom and tranquility. The atmosphere feels warm, spiritual, and quiet, filled with gentle golden tones. A small incense burner emits light smoke nearby.”
Tips
- Be specific about lighting, style, color, and mood.
- Negative prompting can help remove things you do not want, like text or watermarks.
- Check licenses if you plan to use generated images commercially.
3) Image → Text
What it is
You provide an image, the model returns text. This could be a caption that describes the scene, or OCR that extracts text from the image.
Useful models
- Captioning: Salesforce/blip-image-captioning-base
- OCR: microsoft/trocr-base-printed, microsoft/trocr-base-handwritten
Quick examples
Captioning:
from transformers import pipeline
pipe = pipeline("image-to-text", model="Salesforce/blip-image-captioning-base")
result = pipe("https://miro.medium.com/v2/resize:fit:1400/0*4JRXMGNuA7FLG2KR.png")
print(result)OCR:
from transformers import pipeline
pipe = pipeline("image-to-text", model="microsoft/trocr-base-printed")
result = pipe("https://miro.medium.com/v2/resize:fit:1400/0*4JRXMGNuA7FLG2KR.png")
print(result)
Where it helps
Alt text for accessibility, extracting text from scans and screenshots, organizing photo libraries.
Tips
Clean, high-contrast images work best. Handwriting is harder and may need fine-tuning for your data.
4) Text → Video
What it is
You write a prompt or short script, the model generates a short video clip.
Typical models
Sora, Veo.
Example structure
Short videos often work better when you break your idea into scenes with timing, camera notes, and sound cues.
Scene 1 — The Gate (0:00–0:10)
Visual: A close-up shot of a steel gate creaking open. The man enters slowly.
Ambient sound: birds chirping, distant laughter of children.
Camera: Follows from behind, framing the park coming into view.
Narration (soft voice):
“As he steps in, the world feels alive — laughter, footsteps, and whispers weave through the air.”
Scene 2 — The Park Alive (0:10–0:25)
Visuals:
Families walking, kids playing, people chatting on benches.
Wide shot showing the park’s beauty — trees swaying, sunlight spilling through leaves.
Sound: Children’s laughter, dogs barking, soft breeze.
Camera: Slowly pans across faces and trees.
Narration:
“The park breathes in color and calm — where joy strolls freely among strangers.”
Scene 3 — The Pond (0:25–0:40)
Visuals:
The man glances at the pond in the center — ripples shimmer in orange light.
Fish jump, frogs sit at the edge.
Sound: Water rippling, faint croaks, birds fluttering.
Narration:
“In still waters, life dances — unseen yet vibrant.”
Scene 4 — The Walk (0:40–0:55)
Visuals:
The man walks slowly, wearing a red shirt and black track pants.
The sun dips, sky turns orange and gold.
Birds fly home in the distance.
Sound: Soft wind, faint footsteps, fading laughter.
Narration:
“He walks with the setting sun — the day folding into peace.”
Scene 5 — The Sunset (0:55–1:00)
Visual:
The man stops, looks up — a final shot of the sun sinking behind trees.
Sound: Calm music fades in.
Narration:
“And in that quiet glow, everything feels right.”Reality check
Length and resolution can be limited. Motion consistency is improving but not perfect yet. Keep expectations realistic and iterate.
5) Text → Audio (Text to Speech)
What it is
You give text, the model speaks it aloud. Some models can clone a voice from a short sample.
Models to try
coqui/XTTS-v2, gpt-4o-mini-tts.
Example with Coqui
from TTS.api import TTS
tts = TTS("tts_models/multilingual/multi-dataset/xtts_v2", gpu=True)
tts.tts_to_file(
text="It took me quite a long time to develop a voice, and now that I have it I'm not going to be silent.",
file_path="output.wav",
speaker_wav="/path/to/target/speaker.wav",
language="en"
)Notes
- Get consent before cloning someone’s voice.
- For long-form audio like audiobooks, pay attention to pacing and prosody.
- You can generate narration first, then create visuals to match it, or the other way around.
6) Audio → Text
What it is
You provide speech audio, the model returns a transcript.
Models to look at
Whisper, Wav2Vec 2.0.
Tiny example with Whisper
import whisper
model = whisper.load_model("base")
result = model.transcribe("meeting.mp3")
print(result["text"])Tips
Clear audio improves results. For multi-speaker meetings, consider diarization and punctuation tools during post-processing.
Multimodal models
Not every system fits into a single box. Many newer models can accept and produce multiple modalities. A few examples of workflows people actually use:
- Text prompt to generate an image, then a short TTS voiceover to pair with it.
- An image plus a question to get an explanation, then a follow-up request to turn that into a narrated slide or short clip.
- A photo with text instructions that becomes a stylized video with background music.
When you are choosing tools, think about the end-to-end workflow you want, not just one step in isolation.
Summary table
| Input | Output | Example models | Common uses |
|---|---|---|---|
| Text | Text | Llama, Qwen, Phi, DeepSeek | Chat, summarization, code |
| Text | Image | DALL·E, Stable Diffusion, MidJourney, Flux | Art, design, visualization |
| Image | Text | BLIP, TrOCR | Captions, OCR, accessibility |
| Text | Video | Sora, Veo | Storyboards, ads, prototyping |
| Text | Audio | XTTS-v2, gpt-4o-mini-tts | Narration, assistants, cloning |
| Audio | Text | Whisper, Wav2Vec 2.0 | Transcripts, captions, commands |
Best practices
- Be specific in your prompts. Mention style, lighting, camera, pacing, and emotion when it helps.
- Pick models with the right licenses, languages, and hardware needs for your project.
- Get consent for voices and likenesses. Avoid deceptive content.
- Verify outputs, especially for code and factual claims.
Conclusion
These six modalities cover most of what people mean when they talk about “generative AI.” Once you understand them, it is easier to choose tools and design workflows that fit your goals. Start small, experiment, and iterate. If you are curious about deeper dives, I can follow up with guides on fine-tuning voices, building short text-to-video stories, and chaining multiple modalities into a single pipeline.