TOON: A Data Format Designed for Efficient LLM Communication

TOON (Token Oriented - Object Notation)
JSON has become the most widely used data format in the world. Over the years, formats like XML, YAML, CSV, TSV, and others have served different use cases, but JSON remains the default choice across the web and in most LLM interactions. It is lightweight and relatively compact compared to alternatives, which is why it became the de facto standard.
However, JSON was never designed with LLMs in mind. Every large language model operates within a strict context window, which limits how much information can be sent in a single prompt. The larger the prompt, the more tokens we consume. More tokens also mean higher latency and increased cost.
The largest models support millions of tokens, while others offer only a few hundred thousand. As context windows grow, the number of tokens sent becomes a critical factor. Saving even 10 to 20 percent of tokens can significantly reduce cost and noticeably improve speed.
| Rank | Model Name | Context Window (Tokens) |
|---|---|---|
| 1 | Magic.dev LTM-2-Mini | 100000000 |
| 2 | Llama 4 Scout | 10000000 |
| 3 | MiniMax-Text-01 | 4000000 |
| 4 | Gemini 2.0 Pro | 2000000 |
| 5 | Gemini 1.5 Pro | 2000000 |
| 6 | GPT-4.1 | ~1,000,000 (1,047,576) |
| 7 | Gemini 2.5 Pro | 1000000 |
| 8 | Claude Sonnet 4 | 1000000 |
| 9 | GPT-5 | 400000 |
| 10 | Grok 4 / Qwen3 Max | 256000 |
TOON (Token Oriented - Object Notation)
This is exactly the problem TOON aims to solve. TOON is a new data format created specifically for LLMs.
What is TOON?
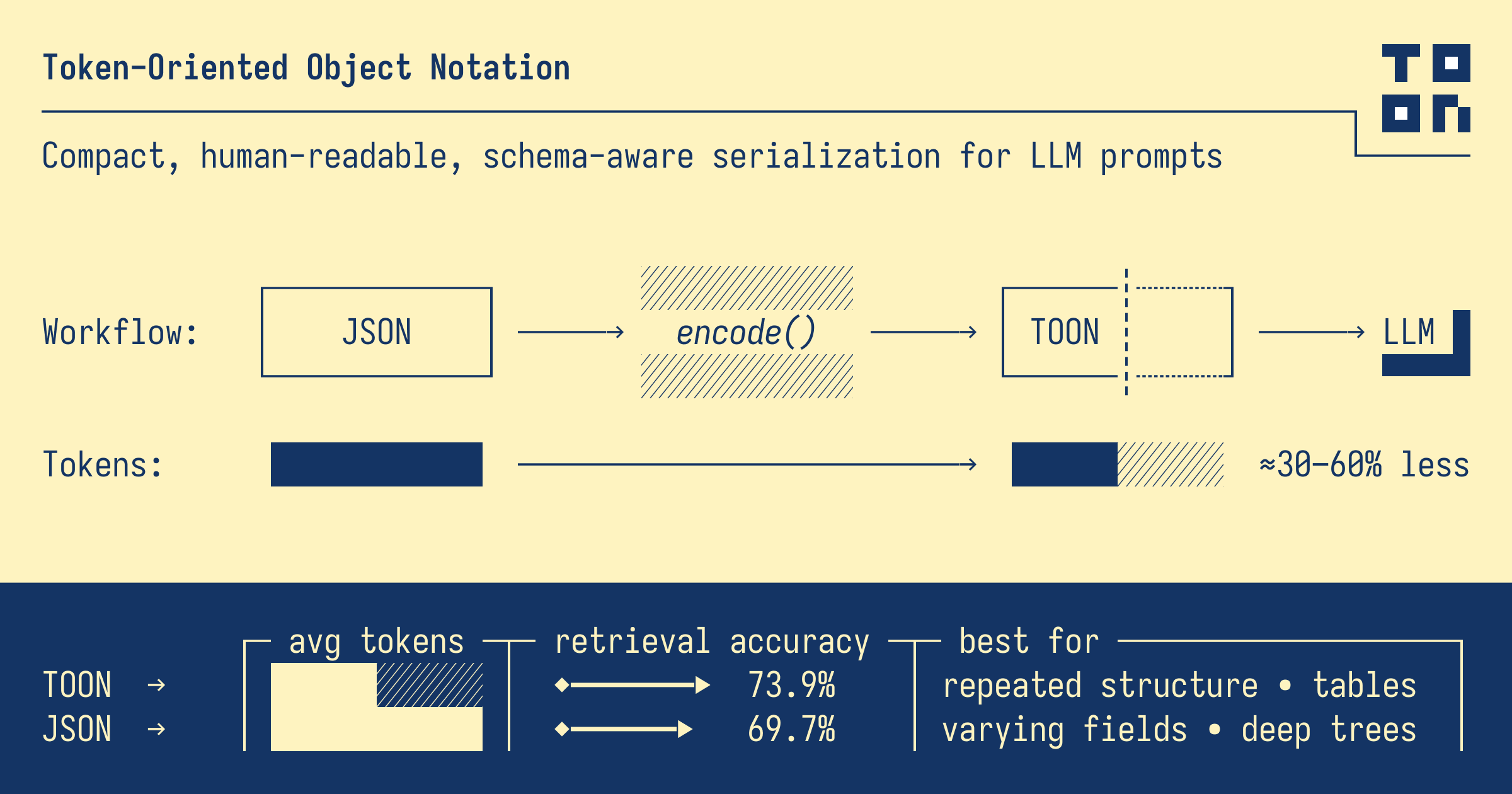
TOON stands for Token Oriented Object Notation. It is a compact, human-readable, schema-aware serialization format optimized for LLM prompts. As shown in the diagram on page 2, TOON fits into the typical workflow by encoding standard JSON into a smaller and more efficient structure before sending it to the model.
The goal is simple: reduce token usage without losing structure or clarity.
TOON performs best with repeated structures, tables, varying fields, and deep trees. In other words, the kind of structured data that is increasingly used in LLM-powered applications.
You can explore the project here:
https://github.com/toon-format/toon
The Python library is under active development:
https://github.com/toon-format/toon-python
JSON vs TOON
Below is a simple example from your provided file.
JSON Format:
{"name": "Alice", "age": 30}
TOON Format:
name: Alice
age: 30
Even in this small example, the TOON version is shorter and more readable. As the structure becomes more complex, the savings grow.
Real-World Token Comparison
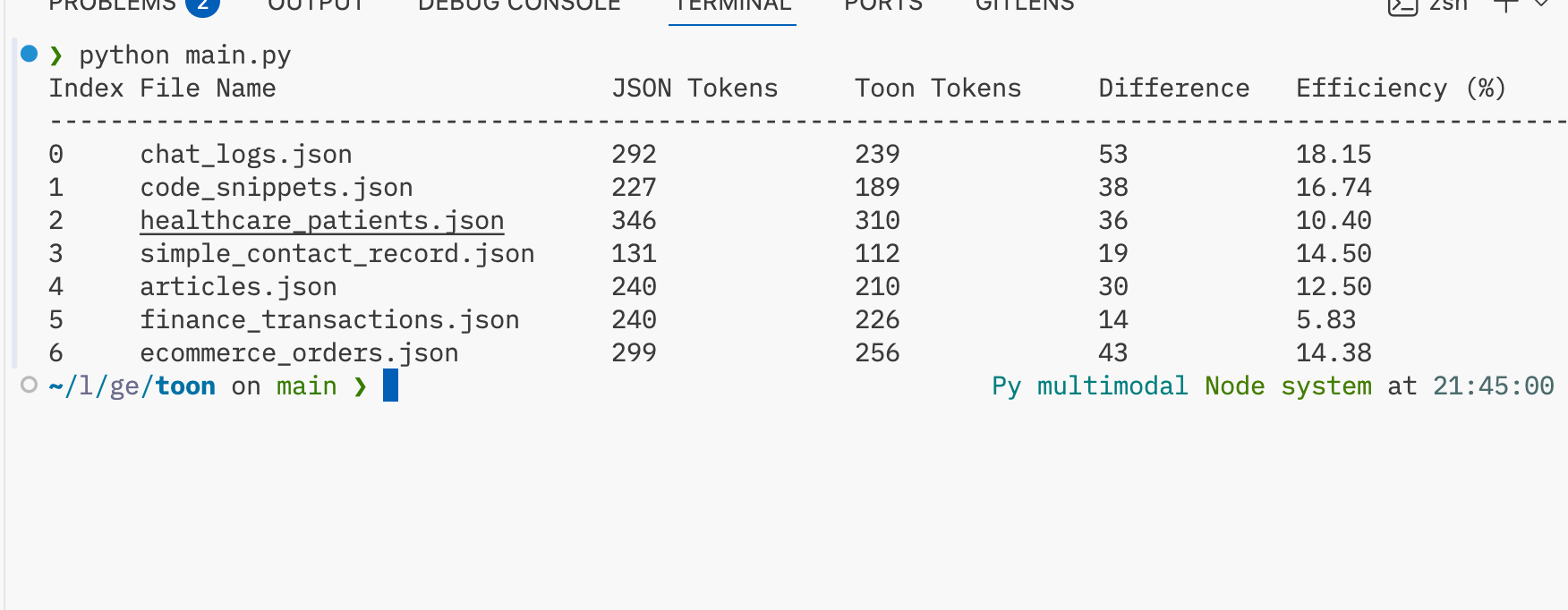
To understand how TOON performs on practical datasets, you tested it across several example JSON files covering ecommerce, CRM, finance, healthcare, and others. The screenshot on page 2 shows the results, with token reductions ranging from about 5 percent to over 18 percent depending on the dataset.
These measurements demonstrate that TOON consistently reduces the number of tokens consumed. Even a modest savings adds up quickly when prompts are large or frequent.
You shared the full comparison code here:
https://github.com/iam-bk/toon
Workflow Integration
According to page 3 of the file, the TOON library supports both encoding and decoding. This means you can maintain JSON as your primary input and output format while using TOON internally to reduce LLM token usage.
TOON (Token Oriented - Object N…
A typical flow would look like this:
- Receive JSON input from the user or application
- Encode into TOON
- Send to the LLM
- Decode the LLM response back into JSON
This approach keeps your existing infrastructure intact while improving performance and reducing cost.
Conclusion
TOON offers a practical way to optimize LLM interactions by shrinking structured data into a more model-friendly format. With measurable token savings, improved prompt readability, and an easy integration path, it is well positioned to become a useful tool for developers building AI-powered systems.
If you work with structured data and regularly hit token limits or deal with high inference costs, TOON is worth exploring.