Tokenizers Explained — The Building Blocks of Language Models
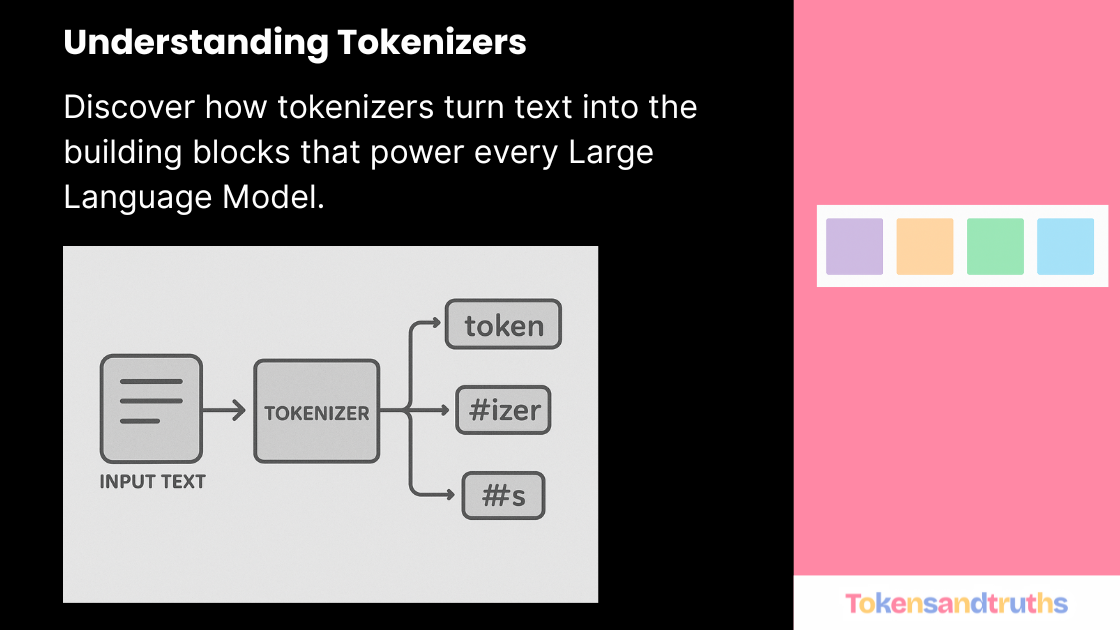
When we interact with any Large Language Model (LLM) — like ChatGPT, Gemini, or Claude — we type in text and receive text back.
But under the hood, these models don’t “see” words.
They process tokens — small chunks of text — one at a time.
If you’ve ever noticed that ChatGPT seems to “think” and type word by word, that’s because it’s generating one token at a time.
What Are Tokens?
When we input a text like:
“What is a large language model (LLM)?”
Before the model can process it, the text must be broken down into tokens — the smallest units the model can understand.
A simple way to tokenize would be splitting by spaces:
["What", "is", "a", "large", "language", "model", "(LLM)?"]
However, this simple approach doesn’t always work — especially for languages without spaces (like Chinese or Japanese) or for words with punctuation and variations.
That’s where advanced tokenizers come in.
Common Types of Tokenizers
1. Word-Based Tokenizers
These split the text by words.
For example:
Input: "AI is amazing"]
Tokens: ["AI", "is", "amazing"
✅ Pros: Simple and intuitive
❌ Cons: Cannot handle new or rare words (e.g., “ChatGPTified”) because they weren’t seen during training.
2. Subword Tokenizers
Subword tokenizers split words into smaller chunks that can still carry meaning.
For example:
Input: "apologized"]
Tokens: ["apolog", "ized"
Here, both “apology” and “apologized” share the root “apolog”.
If a new word like “apologizer” appears, the model can still understand it because it’s built from known subwords.
✅ Pros: Handles new words effectively
❌ Cons: Slightly more complex to train
3. Character Tokenizers
This tokenizer breaks everything down into individual characters.
Input: "AI"]
Tokens: ["A", "I"
✅ Pros: Works for any language or unseen text
❌ Cons: Creates too many tokens — slower and less efficient.
4. Byte Tokenizers
Similar to character tokenizers, but they operate at the byte level (numerical representation of characters).
This is great for handling Unicode characters, emojis, and non-Latin scripts.
✅ Pros: Universal — can represent any text
❌ Cons: More tokens = more computation
Popular Tokenization Algorithms
Now that we understand the types, let’s explore three widely used tokenization algorithms behind modern LLMs.
1. Byte Pair Encoding (BPE)
Used in: GPT Models (OpenAI)
BPE starts with single characters and then repeatedly merges the most frequent pairs to form new tokens.
Example:
Initial tokens: ["l", "o", "w", "e", "r"]Frequent pair: ("l", "o") → merge → "lo"Next: ("lo", "w") → merge → "low"
Over time, “low”, “lowest”, and “lower” might share base tokens like “low”.
✅ Great at compressing common patterns
✅ Efficient for English and similar languages
❌ Not ideal for languages with complex scripts (like Chinese)
2. WordPiece
Used in: BERT, T5, and other Transformer-based models
WordPiece is similar to BPE but selects merges based on likelihood (probability) instead of frequency.
It learns which subwords improve model performance most effectively.
Example:
"playing" → ["play", "##ing"]
Here “##” indicates a continuation of a word — a common convention in WordPiece tokenizers.
✅ Captures semantic meaning
✅ Efficient vocabulary size
❌ Slightly slower training than BPE
3. SentencePiece
Used in: LLaMA, ALBERT, and other multilingual models
SentencePiece doesn’t rely on whitespace at all — it treats the entire text as a continuous stream of characters.
It can tokenize any language, making it perfect for multilingual models.
Example:
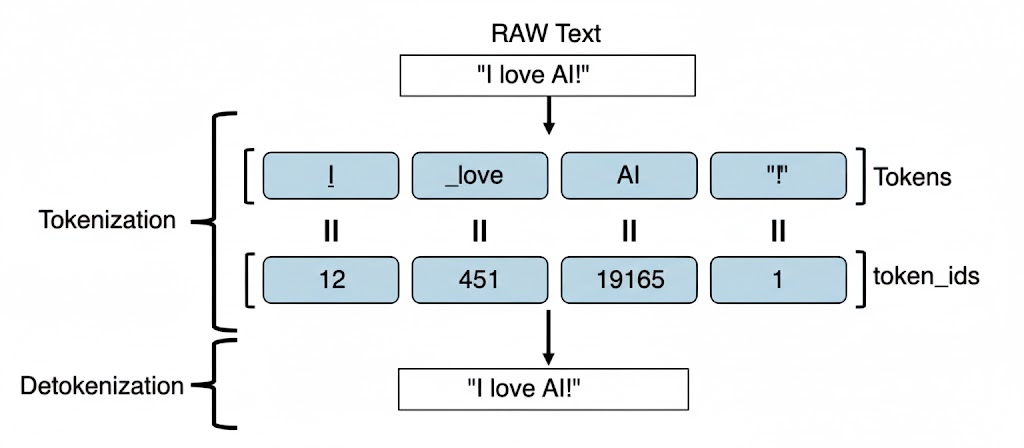
Input: "I love AI!"]
Output: ["▁I", "▁love", "▁A", "I", "!"
The underscore-like symbol ▁ marks the beginning of a new word.
✅ Handles multiple languages and punctuation
✅ Doesn’t depend on pre-tokenized input
❌ Token IDs can be less intuitive to interpret
Try It Yourself — Tokenization in Action
You can use Hugging Face’s transformers library to explore tokenization in different models:
from transformers import AutoTokenizer
def tokenize(model_name, text):
tokenizer = AutoTokenizer.from_pretrained(model_name)
token_ids = tokenizer(text, return_tensors="pt").input_ids
for token in token_ids[0]:
print(">>> " + tokenizer.decode(token))
tokenize("microsoft/Phi-3-mini-4k-instruct", "What is a Large Language Model?")Try swapping different models (like "gpt2" or "bert-base-uncased") to see how each tokenizer breaks the text differently!
Choosing the Right Tokenizer
The tokenizer is not something you choose randomly.
It’s decided during the model’s training phase, because:
- The tokenizer determines how words map to token IDs.
- These IDs correspond to the model’s learned vocabulary.
- Using a different tokenizer than the one used for training will break the model’s understanding.
💡 TL;DR
| Type | Example | Used In | Strength |
|---|---|---|---|
| Word-Based | “AI”, “is”, “amazing” | Early models | Simple |
| Subword | “apolog”, “ized” | WordPiece, BPE | Handles new words |
| Character | “A”, “I” | Rare | Works on any text |
| Byte | Binary encoding | GPT, LLaMA | Universal |
| SentencePiece | “▁AI”, “▁rocks” | LLaMA | Language-agnostic |
Final Thoughts
A tokenizer is like a translator between humans and machines.
It breaks your sentence into tokens, assigns each a numeric ID, and helps the LLM understand what you mean.
In short:
Tokenizer = Text → Tokens → Token IDs → Understanding
Once you grasp this, you’re one step closer to understanding how language models think.