Getting Started with vLLM: Scalable LLM Inference Made Easy
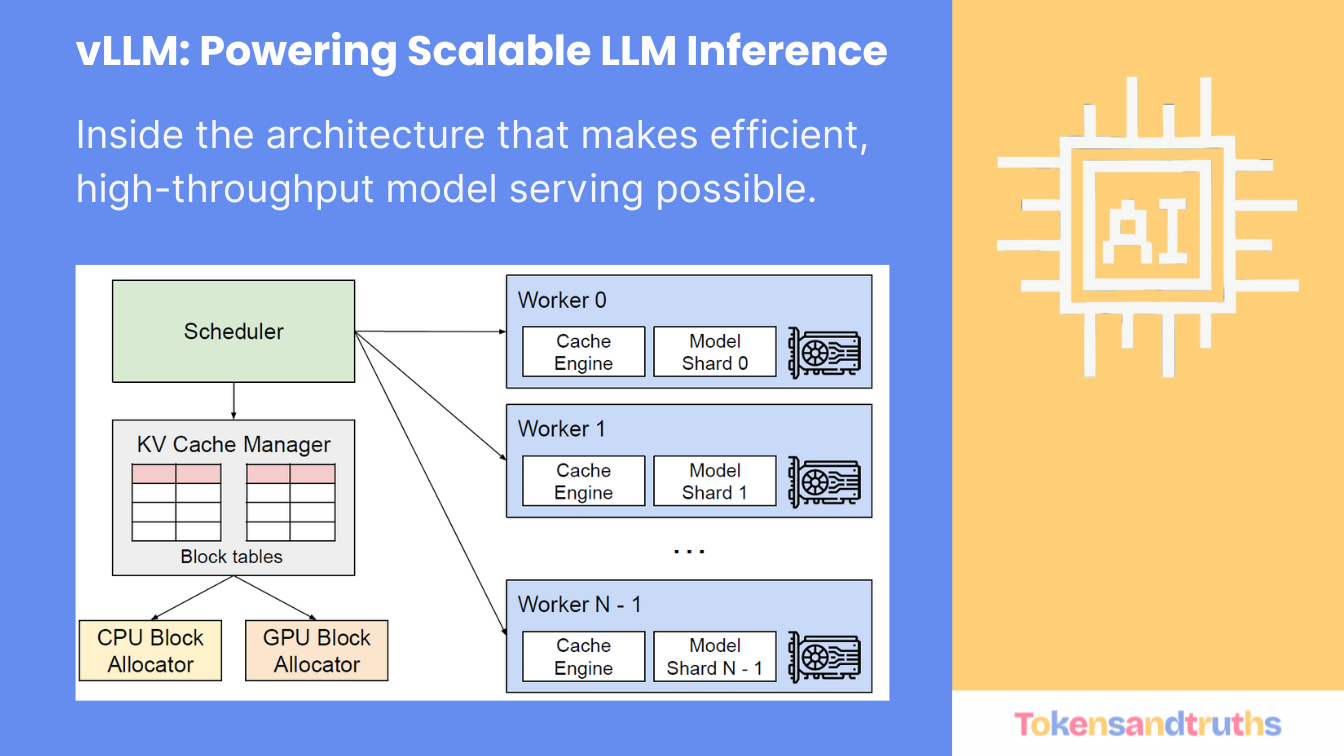
vLLM is an open-source inference and serving engine for Large Language Models (LLMs).
If you’ve ever tried running models using Hugging Face Transformers or llama.cpp, you know that serving multiple concurrent requests efficiently is challenging - especially with limited GPU/CPU resources.
That’s where vLLM shines. It provides optimized techniques for faster and more efficient inference, including:
- Key-Value (K,V) caching to avoid recomputing tokens
- Quantization (FP8, FP16, INT8) to reduce memory footprint
- PagedAttention for smarter memory management
- Continuous batching for better request throughput
- An OpenAI-compatible API server for easy integration
In this post, I’ll walk you through installing and running vLLM locally on macOS Sonoma (M3 Apple Silicon).
For other platforms, please refer to the official vLLM installation guide.
Installation
We’ll use uv, a modern and fast Python package manager.
Install it using:
curl -LsSf https://astral.sh/uv/install.sh | sh
Step 1: Create a working directory
mkdir vllm-demo && cd vllm-demo
Step 2: Create a virtual environment
vLLM requires Python 3.10+. I’m using Python 3.12:
uv venv --python 3.12
Step 3: Clone the vLLM source
Currently, there’s no precompiled vLLM binary for macOS (Apple Silicon), so we’ll build it from source:
git clone https://github.com/vllm-project/vllm.git
cd vllmStep 4: Install dependencies
Try installing dependencies using:
uv pip install -r requirements/cpu.txt
If you encounter version conflicts, this command works better:
uv pip install --index-strategy unsafe-best-match -r requirements/cpu.txt
Step 5: Build and install vLLM
uv pip install -e .
That’s it - vLLM is now installed locally.
Running Your First Inference API
Let’s start a local API server using a lightweight model so it fits into your system memory.
We’ll use microsoft/Phi-3-mini-4k-instruct:
python3.12 -m vllm.entrypoints.api_server \
--model microsoft/Phi-3-mini-4k-instruct \
--disable-sliding-windowSince we’re running on CPU, we disable the sliding window feature (it’s GPU-optimized).
If everything goes well, you’ll see output like:
INFO: Started server process [28887]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)Your inference server is now live at http://localhost:8000
Making Requests to the Inference API
You can use the simple client provided in the vLLM examples:
Try it out:
python3.12 api_client.py --prompt "Who is the director of Batman?"
Output example:
Prompt: 'Who is the director of Batman?'
Beam candidate 0:
"The director of the 1989 film 'Batman' is Tim Burton."You can increase --max-tokens from the default 16 to 100 or more for longer outputs.
Why Use vLLM?
| Feature | What It Does |
|---|---|
| PagedAttention | Efficient memory management by splitting the attention Key/Value cache into “pages” - reducing fragmentation and memory waste. (Red Hat, arXiv Paper) |
| Continuous Batching | Dynamically merges incoming requests into active batches to keep hardware fully utilized - no more waiting for a full batch before inference. (Designveloper) |
| Optimized Kernels & Quantization | Support for quantized models (INT8, FP8, FP16) and optimized GPU/CPU kernels, integrating with high-performance libraries like FlashAttention. (Docs) |
| Streaming + OpenAI-Compatible API | Supports real-time streaming token generation and an OpenAI-compatible API for seamless integration with existing clients. |
Conclusion
vLLM is an excellent choice if you want high-performance, scalable, and OpenAI-compatible LLM inference - without relying on expensive cloud endpoints.
It brings production-grade features like continuous batching, paged attention, and streaming responses right to your local setup.
Whether you’re experimenting with small models on a MacBook or deploying large models on GPUs in production, vLLM offers a fast and flexible foundation for serving LLMs efficiently.